
DeepSeek频繁的答复“服务器很忙,请稍后再试”正在使来自世界各地的用户疯狂。
DeepSeek是公众不众所周知的,以启动V3语言模型而闻名,该模型于2024年12月26日基准GPT 4O。1月20日,DeepSeek发布了R1型语言Model R1,该语言Model R1对Openai O1进行了基准测试。后来,该公司具有由“深思熟虑”模型产生的高质量答案及其创新,揭示了一个积极的信号,即模型培训的成本可能在模型培训的早期阶段就会暴跌。并且该应用程序完全不在圆形之外。从那时起,DeepSeek R1一直在遇到拥堵,其网络搜索功能间歇性瘫痪,并且Deep Thinker模式具有较高的促使“服务器忙碌”的频率,这使许多用户困扰了大量用户。
十多年前,DeepSeek开始体验服务器中断。 1月27日中午,DeepSeek的官方网站多次表明“ DeepSeek网页/API不可用”。那天,DeepSeek成为周末下载最高iPhone的应用程序,并在美国地区下载。超越chatgpt。
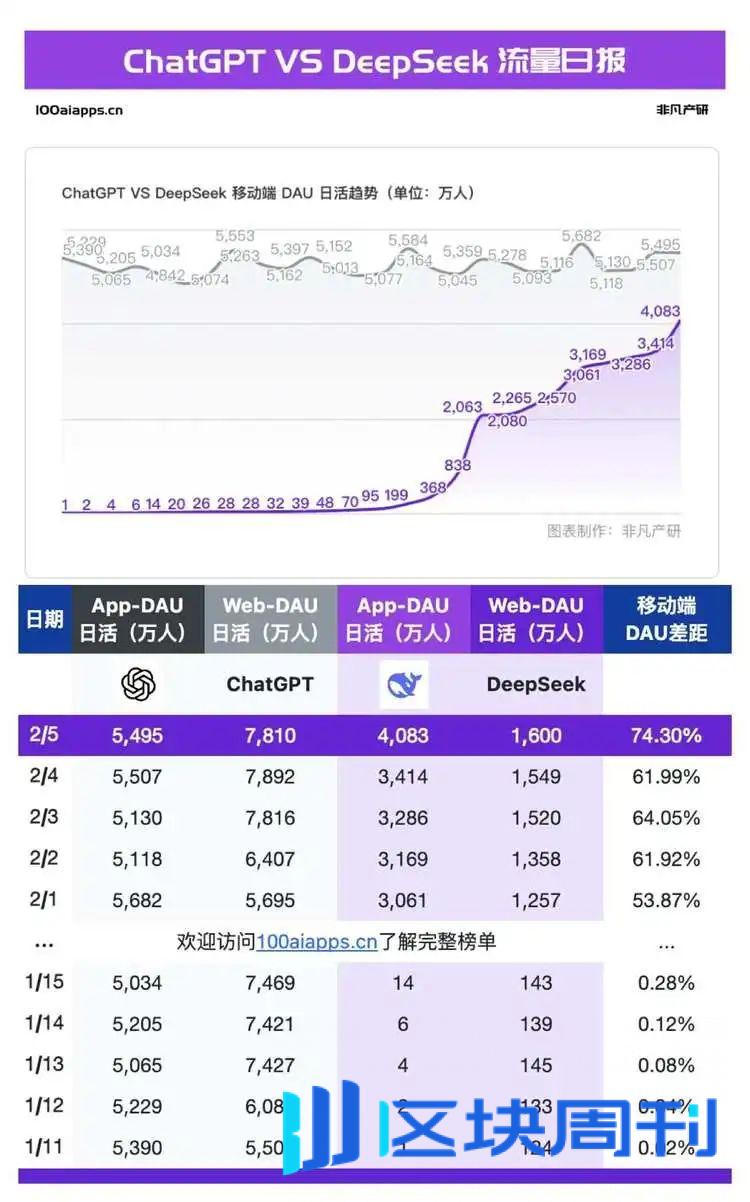
2月5日,DeepSeek的移动终端启动了26天,每日活跃用户超过4000万,Chatgpt的移动终端的日常活跃用户达到了5495万,而DeepSeek占Chatgpt的74.3%。陡峭的增长曲线从DeepSeek中出现了,有关其繁忙服务器的抱怨连续出现,当被问及一些问题时,世界各地的用户开始遇到停机时间的不便,并且开始出现各种替代访问,例如Deepseek's's替换网站。主要的云服务提供商,芯片制造商和基础设施公司都在线,个人部署教程也无处不在。但是人们的疯狂并没有放松:世界上几乎所有重要的制造商都声称支持DeepSeek的部署,但是各地的用户仍在抱怨服务的不稳定。
这到底发生了什么?
1。习惯的人无法忍受无法打开的deepseek
人们对“忙碌的DeepSeek服务器”的不满是从以前主要关注Chatgpt的顶级AI应用程序很少存在滞后的事实。
尽管Chatgpt经历了自开放服务推出以来的几个P0级(最糟糕的事故)停机时间,但总体而言,它相对可靠,并且在创新和稳定之间找到了平衡,并且逐渐变得相似。传统云服务的关键组成部分。

chatgpt不是很大的停机时间
Chatgpt的推理过程相对稳定,包括两个步骤:编码和解码。编码阶段将输入文本转换为向量,并且向量包含输入文本的语义信息。在解码阶段,Chatgpt使用先前生成的文本作为上下文,通过变压器模型生成下一个文本。单词或短语为止,直到产生满足需求的完整陈述为止。大型模型本身属于解码器(解码器)体系结构。解码阶段是令牌的输出过程(大型模型处理文本时最小的单元)。每当提出问题时,都会开始一个推理过程。
例如,如果您问Chatgpt:“您今天感觉如何?”,Chatgpt将编码此句子以生成每一层的注意表示。基于所有先前令牌的注意力表示,可以预测第一个输出令牌。我。我”,获得新的注意力表达,然后预测下一个令牌:“ the”,然后遵循第一步,第二步,骑自行车,最后得到“您今天感觉如何?我心情很好。”
Kubernetes是一种精心策划容器的工具,是Chatgpt的“幕后指挥官”,该工具负责调度和分配服务器资源。当用户承载者的涌入完全超过Kubernetes控制平面的容量时,它将导致CHATGPT系统的完全故障。
Chatgpt的瘫痪总数并不多,但是这是它所依赖的支持的强大资源。维持稳定操作的强大计算能力是人们忽略它的地方。
一般而言,由于推理处理的数据比例通常很小,因此计算能力的要求不如培训。一些行业内部人士估计,在正常的大规模模型推理过程中,视频记忆模型参数的主要权重占多数,约为80%。现实情况是,在Chatgpt的多个内置模型中,默认模型大小小于DeepSeek-R1的671b。此外,Chatgpt的GPU计算能力比DeepSeek具有更多的GPU计算能力,这自然表明它比DS-R1更多。稳定的性能。
DeepSeek-V3和R1都是671b模型。模型启动过程是推理过程。推理期间的计算功率储备需要与用户数量形成鲜明对比。例如,如果有1亿用户,则需要配备有1亿用户的图形卡。它在培训期间巨大,独立于计算功率储存,与计算功率储备无关。从各方,DS的图形卡和计算功率储备的信息来看,显然不足,因此经常会偶然发现它们。
这种比较使得适应Chatgpt丝滑体验的用户不习惯,尤其是当他们对R1的兴趣增加时。
2。卡,卡或卡
此外,如果仔细比较它,Openai和DeepSeek遇到的情况会大不相同。
前者得到了微软的支持。作为OpenAI的独家平台,Microsoft Azure Cloud Service配备了Chatgpt,Dalle-E 2 Image Generator和Github Copilot自动编码工具。从那以后,这种组合已成为云 + AI的经典范式,并且很快受欢迎已成为行业标准。尽管后者是一家初创企业,但在大多数情况下,它依赖于自行构建的数据中心,类似于Google,并且不依赖第三方云计算提供商。在审查了公众信息之后,硅星发现,DeepSeek尚未开始与云制造商和芯片制造商合作(尽管云制造商宣布他们会让DeepSeek模型在春季音乐节上运行,但他们没有进行任何操作真正的合作)。
此外,DeepSeek遇到了前所未有的用户增长,这意味着与CHATGPT相比,它为压力状况做准备的时间少。
DeepSeek的良好性能来自硬件和系统级别的整体优化。 DeepSeek的母公司Huanfang量化最早在2019年就花费了2亿个超级计算机群集,以建造Firefly 1超级计算机集群。到22年,它已经默默存储了10,000张A100图形卡。为了提供更有效的并行培训,DeepSeek开发了自己的HAI LLM培训框架。该行业认为,萤火虫群可以使用数千至成千上万的高性能GPU(例如NVIDIA A100/H100或国内芯片)来提供强大的平行计算功能。目前,Firefly群集支持训练DeepSeek-R1和DeepSeek-Moe等模型。这些模型在复杂的任务(例如数学和代码)中执行接近GPT-4级别。
Firefly群集代表了DeepSeek在新的建筑和方法中的探索过程,也使外界相信,通过这种创新技术,DS降低了培训成本,只有最先进的西方模型的计算能力只有一小部分可以是用过的。训练了与顶级AI模型的性能相当的R1。半分析计算得出的是,DeepSeek实际上具有巨大的计算功率储备:DeepSeek总共建造了60,000张NVIDIA GPU卡,其中包括1.0,000亿架100万,1.0,000 h100万,10,000个特殊版本“ H800和30,000” Special Edition“ H20” H20。
这似乎意味着R1卡体积相对足够。但是实际上,R1作为推理模型,是Openai的O3的目标。这种推理模型需要为响应过程部署更多的计算能力,但是DS在培训成本方面保存的计算能力随着推理成本方面的急剧增加,目前尚不清楚哪个计算能力更高,哪个是一个较低。
值得一提的是,DeepSeek-V3和DeepSeek-R1都是大型语言模型,但它们的操作方法很差。 DeepSeek-v3是一种指令模型,类似于chatgpt,接收提示单词以生成相应的文本以进行回复。但是DeepSeek-R1是推理模型。当用户询问R1时,它将首先执行大量推理过程,然后生成最终答案。 R1生成的令牌中出现的第一件事是大量思考链过程。在生成答案之前,该模型将首先解释问题并分解问题。所有这些推论过程将以令牌的形式迅速生成。
Yaotu Capital副总裁Wen Tingcan认为,上述DeepSeek巨大的计算功率储备是指培训阶段。计算能力团队可以计划和预测。缺乏计算能力并不容易,但是推理计算能力相对不确定。因为它主要取决于用户量表和用法,所以它是相对弹性的。 “推理计算能力将根据某些规则增长,但是随着DeepSeek成为一种现象级产品,用户规模和用法在短时间内爆炸性增加,这会导致对计算能力的需求在推理阶段爆炸性增加,所以有一个滞后。”
立即活跃的模型产品设计师,独立开发人员隐藏了DeepSeek滞后的主要原因的卡数。他认为,DS是世界140个市场下载量最高的移动应用程序,无论如何都无法坚持。 ,即使您使用新卡也行不通,因为“用新卡制成云需要时间”。
“运行芯片的成本,例如NVIDIA A100,H100,一小时的H100具有公平的市场价格。从输出令牌的推理成本来看,DeepSeek比OpenAI的类似型号便宜90%以上,这与每个人的计算都没有太大不同,因此模型体系结构Moe本身不是主要问题,但是GPU DS的数量可以决定它们每分钟可以产生的最大令牌。上限是“ AI本机应用程序填充光的开发人员Chen Yunfei,也有类似的视野。
一些行业内部人士还向硅Starman提到,DeepSeek滞后的本质是,私有云的做法不是很好。
黑客攻击是R1滞后的另一个驱动因素。 1月30日,媒体从网络安全公司Qi'Anxin中学到,对DeepSeek在线服务的攻击强度突然升级了,与1月28日相比,其攻击指示增加了数百次。Qi'anxinXlab观察到至少2个Botnets参与了袭击。
但是,似乎有一个明显的解决方案来解决R1自己的服务,这是由第三方提供的。这也是我们在春节期间目睹的最活跃的景观 - 各种制造商都部署了服务来承担人们对DeepSeek的需求。
1月31日,NVIDIA宣布NVIDIA NIM可以使用DeepSeek-R1。此前,由于DeepSeek,Nvidia的市场价值在一晚上蒸发近6000亿美元。同一天,Amazon Cloud AWS用户可以在其人工智能平台Amazon Bedrock和Amazon Sagemaker AI中部署最新的R1 DeepSeek基本模型。随后,包括困惑和光标在内的AI应用程序也包括了连接的DeepSeek。微软领先于在亚马逊和Nvidia之前在云服务Azure和Github上部署DeepSeek-R1。
从2月1日的农历新年的第四天开始,华为云,阿里巴巴云,火山发动机和Bytedance的子公司腾讯云也加入了该公司。他们通常提供DeepSeek全系列和全尺寸模型部署服务。然后是AI芯片制造商,例如Biren Technology,Hanbo半导体,Ascend和Muxi。他们声称适用于原始的DeepSeek版本或较小的蒸馏版本。在软件公司,Ufida,Kingdee等方面,在某些产品中连接到DeepSeek模型,以增强产品实力。最后,一些终端制造商(如联想,华为和荣誉)的产品与DeepSeek型号相连,并用作终端的个人助理和汽车智能驾驶舱。 。
到目前为止,DeepSeek依靠自己的价值来吸引一大批朋友,包括云制造商,运营商,证券公司和国内外的国家超级计算互联网平台。由于DeepSeek-R1是一个完全开源的模型,因此所有访问服务提供商已成为DS模型的受益人。一方面,这大大增加了DS的声音体积,还引起了更频繁的滞后。服务提供商和DS本身越来越被用户涌入所困扰,但他们尚未找到解决稳定使用问题的解决方案。关键技巧。
考虑到DeepSeek V3和R1的原始版本具有高达6710亿个参数,适用于在云上运行。云制造商本身具有更多的计算能力和推理能力。他们推出与DeepSeek相关的部署服务是降低企业使用的门槛。部署DeepSeek模型后,向公众提供了用于提供DS模型的API。与DS本身提供的API相比,它被认为提供了比DS官员更好的用户体验。
但是实际上,DeepSeek-R1模型本身的经验问题尚未在各种服务中解决。外界认为,服务提供商并不缺少卡,但实际上,他们部署的R1对开发人员具有不稳定的反应经验。反馈的频率与R1完全相同,这更多是因为可以将可以分配给R1进行推理的卡数量不多。

“ R1的受欢迎程度仍然很高,服务提供商需要考虑其他访问模式。可以提供给R1的卡非常有限,R1的受欢迎程度很高。一旦公司进入R1并提供了它一个相对较低的价格,它将分解。
模型部署优化是一个涵盖许多链接的广泛领域。从培训完成到实际的硬件部署,它涉及多层次的工作,但是对于DeepSeek的滞后事件,原因可能更简单,例如太大的模型和在线之前。优化的准备不足。
在启动流行的大型模型之前,它将遇到涉及技术,工程,业务等的挑战,例如培训数据和生产环境数据之间的一致性,数据延迟和实时影响模型推理效果,在线推理效率和资源利用率太高。 ,模型概括功能不足以及工程方面,例如服务稳定性,API和系统集成。
许多流行的大型模型在推出之前非常重视推断。这是因为计算时间和内存问题。前者是指漫长的推理延迟,这会导致用户体验差,甚至无法满足延迟要求,例如滞后。 ,后者是指大量的模型参数,这些参数消耗了视频内存,即使无法放下单个GPU卡,也会导致滞后。
温丁卡(Wen Tingcan)解释了硅星人的原因。他说,服务提供商在提供R1服务方面遇到了挑战。本质是DS模型结构是特殊的,模型太大 + MOE(专家混合结构,一种有效的计算方法)架构,“(服务提供商)优化需要时间,但是市场受欢迎程度有一个时间窗口,所以我们将首先上升然后进行优化,而不是在完整优化后上网。”
如果R1想要稳定运行,那么现在的核心在于预备役和推理方面的优化功能。 DeepSeek需要做的是找到一种方法来降低推理成本,减少卡的输出以及单输出令牌的数量。
同时,滞后还表明DS的计算功率储量可能不如半分析大。 Huanfang基金公司需要使用卡,而DeepSeek培训团队也需要使用卡。没有多少卡可以将用户运送到用户。根据当前的发展情况,DeepSeek可能不会在短期内花钱租用服务,然后为用户免费提供更好的体验。他们更有可能等到第一波C-End业务模型进行整理之前,然后考虑服务租赁问题。这也意味着滞后将持续很长时间。
“他们可能需要两个步骤:1)制定付款机制以限制免费用户模型的使用; 2)寻找云服务制造商合作并使用其他人的GPU资源。”开发商Chen Yunfei给出的临时解决方案在行业中是相当共识的。
但是目前,DeepSeek对其“繁忙的服务器”问题并不焦虑。作为一家追逐Agi的公司,DeepSeek似乎不愿意将过多关注用户流量的涌入。将来,也许用户仍然必须习惯面对“繁忙的服务器”接口。