
Grok3的消耗是DeepSeek V3的计算能力的263倍,是吗?
2月18日,北京时间,马斯克和XAI团队在直播期间正式发布了最新版本的Grok3。
在这次新闻发布会上很久以前,依靠提供各种相关信息以及Musk自己的24/7不间断预热和炒作,全球对Grok3的期望被推到了前所未有的水平。一周前,当马斯克在现场广播中对DeepSeek R1发表评论时,他自信地说:“ XAI将很快推出更好的AI模型。”
从现场显示的数据来看,Grok3在数学,科学和编程基准测试中超过了所有当前主流模型。马斯克甚至声称将来将在SpaceX Mars任务计算中使用GROK3,并预测“它将在三年内实现”。诺贝尔奖级别的突破”。
但是这些只是马斯克的话。发行后,作者测试了GROK3的最新Beta版本,并提出了用于使大型模型变得困难的经典问题:“哪个更大,9.11或9.9?”
不幸的是,在不添加任何归因或标签的情况下,GROK3当前是最聪明的,仍然无法正确回答此问题。
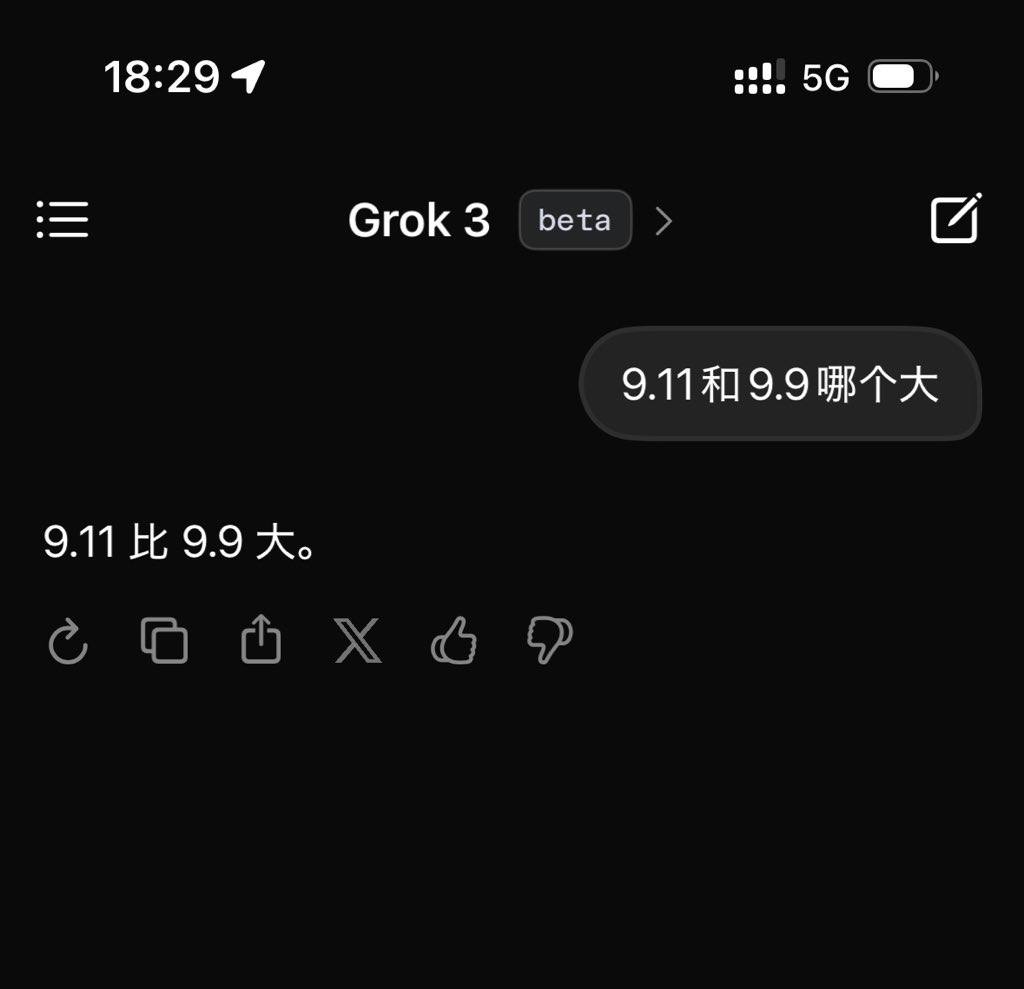
GROK3并未准确识别此问题的含义|照片来源:极客公园
发布该测试后,它很快在很短的时间内引起了许多朋友的注意。巧合的是,海外有许多类似的测试,例如“两个球首先落在比萨的倾斜塔上”,而这些基本的物理/数学问题,Grok3也被发现仍然无法应付。因此,它被昵称为“天才不愿回答简单的问题”。
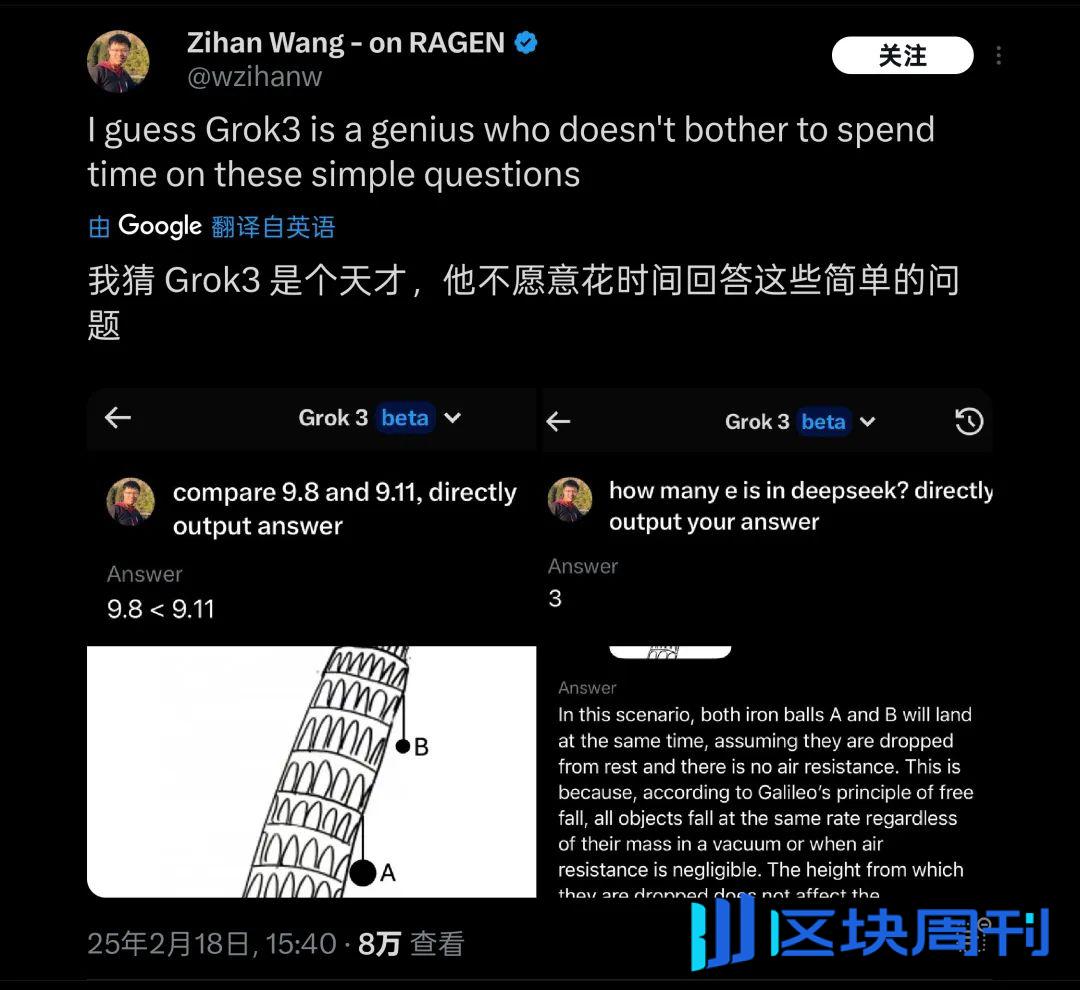
Grok3在实际测试中的许多常识问题上“翻倒” |图像来源:x
除了对网民自发测试的基本知识外,GROK3还失败了。在XAI新闻发布会的实时广播中,马斯克展示了Grok3的使用来分析流亡道路2的相应职业和升华效果,他声称这经常发挥作用。但是实际上,GROK3给出的大多数相应答案都是错误的。直播中的马斯克没有看到这个明显的问题。
GROK3在实时广播中还遇到了很多错误|图像来源:x
因此,这个错误不仅是一个可靠的证据,表明海外网民再次嘲笑马斯克在玩游戏中“寻找代理人”,而且再次对Grok3在实际应用中的可靠性中添加了一个很大的问号。
对于这样的“天才”,无论其实际能力如何,都会质疑如此复杂的应用程序场景(例如火星勘探任务)的可靠性。
目前,几周前有资格参加GROK3测试的许多人昨天使用几个小时的人指出了有关Grok3当前表现的同样结论:
“ Grok3很好,但不比R1或O1-Pro好”

“ grok3很好,但并不比R1或O1-Pro好” |图像来源:x
GROK3在大型型号聊天机器人竞技场发行的官方PPT中取得了“领先”,但这实际上也应用了一些小的绘图技能:列表的垂直轴只列出了1400-1300点,该部分的排名是最初的1%测试结果差距在此PPT显示中极为明显。
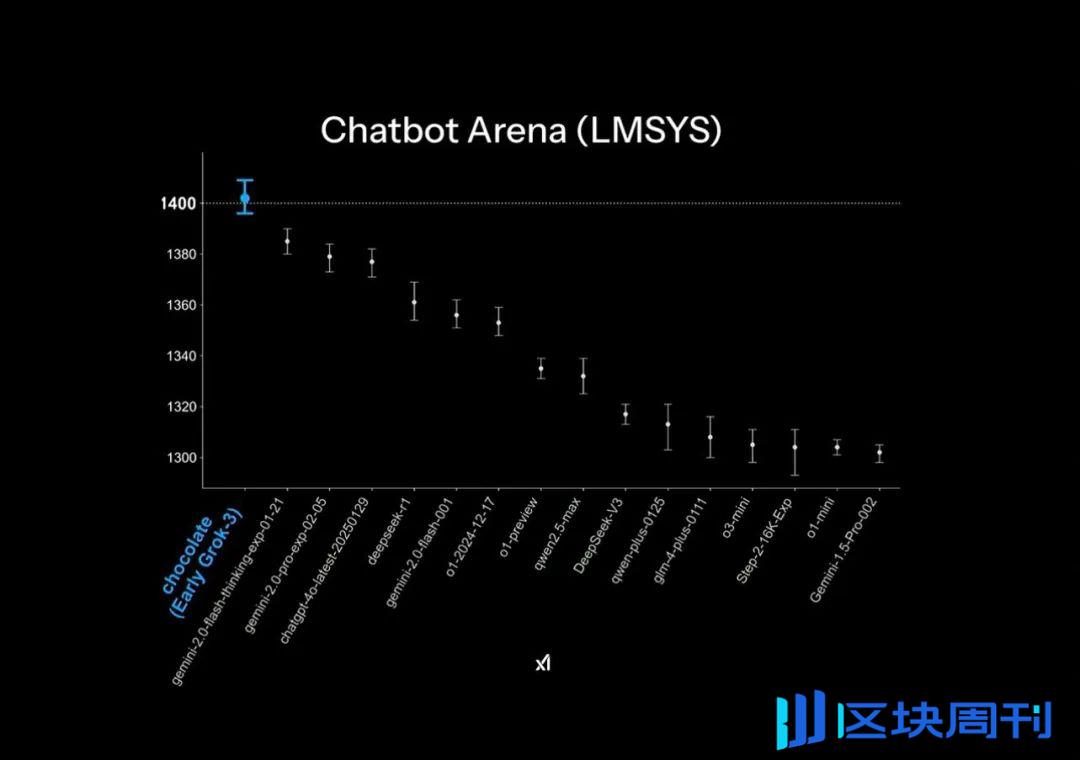
正式发布了PPT中的“远后”效应|图像来源:x
至于实际的模型得分结果,与DeepSeek R1和GPT4.0相比,GROK3实际上仅达到的差距低于1-2%:这对应于许多用户在实际测试中的体感效应。

实际上,Grok3仅比后来者高1%-2%|图像来源:x
此外,尽管GROK3超过了当前在公开场合进行测试的所有模型,但这并不是许多人购买的:毕竟,Xai在Grok2时代的列表中是“得分点”,并且随着列表的答案的长度,列表的答案在答案的长度上得到了回答。在减轻体重和大大降低分数的情况下,行业内部人士通常会以“高分和低能力”来批评它。
无论是列表中的“吸引得分”,还是图形设计中的“小技巧”,它们都表明了Xai和Musk的痴迷,因为模型功能在“领先”。
对于这些差距,价格麝香的价格很高:在新闻发布会上,马斯克在几乎炫耀的音调中使用了200,000 H100(Muske在直播中说,他使用了H100的“超过100,000”)训练GROK3 ,总培训时间达到了2亿小时。这使某些人认为这是GPU行业的另一个主要好处,并认为DeepSeek造成的冲击是“愚蠢的”。
许多人认为,堆叠计算能力将是模型培训的未来|图像来源:x
但是实际上,一些网民比较了通过使用2,000 H800培训在两个月内获得的DeepSeek V3,并计算出GROK3的实际训练计算功耗是V3的263倍。 Deeseek V3和Grok3之间的差异在大型赛场上获得1,402分甚至不到100分。
这些数据发布后,许多人很快意识到,Grok3的顶级“世界上最强大”的背后,这种逻辑是,模型越大,并且性能越强,则已经显示出明显的边缘效应。
即使是“高分和低能量”的GROK2,也得到了X(Twitter)平台中大量高质量的第一方数据的支持。在GROK3培训方面,XAI自然会遇到Openai当前还遇到的“天花板” - 高质量培训数据的不足,这将迅速揭示模型能力的边际效应。
最深入地意识到和了解这些事实的第一个人绝对是Grok3开发团队和马斯克。因此,马斯克还一直在社交媒体上说,用户当前版本只是“仅是beta版本”,“完整”该版本将在未来几个月内发布。“马斯克本人已成为GROK3和GROK3和建议用户直接反馈评论区域中使用中遇到的各种问题。

他可能是地球上最多的球迷的产品经理|照片来源:X
但是在不到一天的时间里,Grok3的表现无疑向后来的后续者发出了警报,他们希望依靠“ Dali Fei Brick”来训练更强大的大型模型:根据Microsoft的信息,OpenAI GPT4参数卷为1.8。与GPT3相比,参数增加了10倍以上,而传闻的GPT4.5参数量甚至更大。
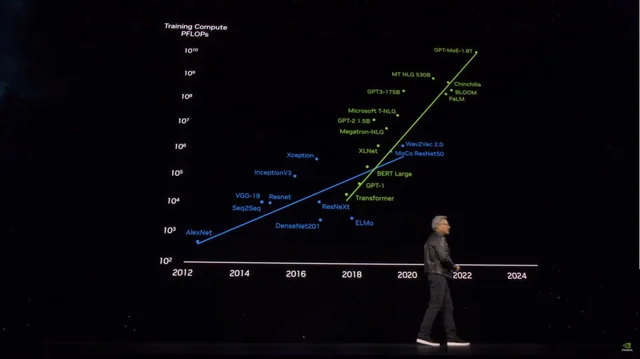
培训成本飙升时,模型参数的数量飙升|图像来源:x
借助GROK3,GPT4.5和更多希望继续“燃烧的钱”并使用参数量获得更好模型性能的玩家必须考虑如何突破已经接近您的天花板。
目前,Openai前首席科学家Ilya Sutskever在12月表示:“我们熟悉的预培训将结束”,并再次被人们铭记,并试图为大型模型培训找到真正的出路。

伊利亚的观点听起来是对行业的警钟|照片来源:X
当时,ILYA准确预见了可用的新数据接近耗尽的情况,并且该模型无法通过获得数据继续提高性能。这种情况被描述为化石燃料的消费,称“就像石油是有限的资源一样”,互联网也是人类产生的内容也受到限制。”
在Sutskever预测中,预训练模型之后的下一代模型将具有“真正的自主权”。同时,您将有能力“像人类大脑”进行推理。
与当今的预培训模型主要依赖的内容匹配(基于模型所学的内容)不同,未来的AI系统将能够逐渐学习并建立一种方法来解决问题,以类似于“思考”的方式人脑。
人类具有一定学科的基本水平,只需要基本的专业书籍才能实现它,但是AI模型需要学习数百万个数据才能达到最基本的入门效果,即使您在此之后更改问题时,这些基本问题也无法正确理解,并且该模型在实际智能中尚未得到改善:文章开头提到的Grok3仍无法正确回答的基本问题是这种现象的直观表现。
但是,除了“强大而强大的砖块”之外,如果Grok3确实可以揭示“预先培训的模型将要结束”该行业的事实,它仍然会给该行业带来很大的灵感。
也许,随着Grok3狂潮逐渐消失,我们还可以看到更多的案例,例如“基于特定数据集的高性能模型进行微调的高性能模型”。在这些探索中,我们终于找到了通往AGI的真正途径。