
2月18日,Kimi和DeepSeek在同一天发布了新的进展,即MOBA和NSA,这两者都对“注意机制”进行了改进。
今天,MOBA的一名主要研发学生安德鲁·卢(Andrew Lu)在齐胡(Zhihu)上发表,讲述了研发过程中的三个陷阱,他称之为“三个进入思想悬崖”。他在Zhihu上的签名是“新LLM培训师”。
此答案下的评论是:“从开源论文和开源代码中,它已经演变为开源思维链。”
注意机制很重要,因为它是当前大语言模型(LLM)的核心机制。回到2017年6月开始LLM Revolution的Transformer八纸纸上,标题是:您需要注意的全部。到目前为止,该文件已被引用153,000。
注意机制允许AI模型知道在处理信息时要“专注”和“忽略”的内容,并掌握信息的最关键部分。
大型模型的训练和使用(推理)阶段,注意机制发挥了作用。它在输入数据(例如“我喜欢吃苹果”)时粗略地起作用,大型模型将计算句子和其他单词中每个单词(令牌)之间的关系,从而了解语义和其他信息。
由于大型模型需要处理越来越长的上下文,因此标准变压器最初采用的全部注意力机制对于使用计算资源而言是难以忍受的,因为原始过程是所有输入词的重要性需要计算。分数是重新加权后最重要的单词,其计算复杂性将随着文本的增长而增加正方形(非线性)。如《 MOBA论文》的“摘要”部分所写:
“传统注意机制固有的平方计算复杂性的增加带来了过度的计算开销。”
同时,研究人员追求可以进行足够长时间处理的大型模型的环境 - 多轮对话,复杂的推理,记忆能力... AGI应该牢记的这些特征需要更长的上下文功能。
如何找到一种不占据如此多的计算资源和内存,不会失去模型性能的注意机制优化方法已成为大型模型研究中的重要主题。
这是几家公司的技术背景,它们将注意力与“注意”联系起来。
除了DeepSeek NSA和Kimi Moba外,另一家中国模型创业公司Minimax还在其第一个开源模型Minimax-01中实现了一种大规模的新注意机制。 Minimax的创始人Yan Junjie当时告诉我们,这是Minimax-01最重要的创新之一。
壁面智能联合创始人刘·齐尤恩(Liu Zhiyuan)兼欣华大学计算机科学系副教授,他还于2024年出版了INFLLM,该大学还涉及稀疏的注意力,并由NSA论文引用。
在这些成就中,NSA,MOBA和INFLLM的注意力机制都属于“稀疏注意机制”(稀疏注意); Minimax-01的尝试主要是另一个方向:“线性注意机制”(线性)注意力)。
Seerateention是Seerateptions的作者之一,Microsoft Asia Research Institute的高级研究员告诉我们:一般而言,线性注意机制越来越根本地变化为标准注意机制。我想直接解决计算学位平方的爆炸,因为文本变得更长(因此,非线性问题的可能成本是它将失去对长上下文的复杂依赖性的捕获;稀疏的注意机制使用了注意力的固有稀疏性尝试找到一种更强大的优化方法。
同时,我想推荐Cao Shijie老师在Zhihu上的赞美答案:
(他回答了一个问题:“哪些信息值得关注Liang Wenfeng发表的DeepSeek新论文的NSA注意机制,它将带来什么影响?”)。
MOA(稀疏注意的混合物)是同事,Fu Tianyu,博士,NICS-EFC实验室,Tsinghua University,他说,在稀疏注意机制的一般方向上:“ NSA和MOBA都引入了动态注意力方法,也就是与使用静态方法相比,需要计算具有细粒度的KV缓存块可以改善模型性能在模型培训中也引入了稀疏的注意力,而不仅仅是推理。
(注意:KV缓存块是一个存储先前计算的关键标签和值值的缓存;其中关键标签是指与注意机制相关的计算中用于识别信息(例如数据特征或数据位置)的标识标签,因此当注意力权重匹配并与其他数据相关联时,可以计算该值,该值值对应于关键标签,通常包含要处理的数据内容,例如单词或短语的语义向量。
同时,除了发布详细的MOBA技术论文外,MOBA工程代码还在GitHub Project网站上发布。这套代码已在月球自己产品的基米中线在线使用了一年多。
*以下是安德鲁·卢(Andrew Lu)对齐胡(Zhihu)的自我报告,该报告已由作者授权。原始文本中有许多AI术语,并且()中的灰色文本解释部分都由编辑注释。原始链接:
安德鲁·卢(Andrew Lu)的研发自我报告
在张老师(Tsinghua University的Zhang Mingxing助理教授)的邀请下,我想回答我以前在MOBA的起伏。我开玩笑地称其为“三个进入思想和幸福”。 (安德鲁·卢(Andrew Lu)回答了一个问题:“如何评估基米(Kimi)的开源稀疏注意框架moba?与DeepSeek的NSA相比,每个人的亮点是什么?”)
MOBA的开始
MOBA项目很早就开始了。在2023年5月底,当刚刚建立了月亮的黑暗面时,他在登记的那天被蒂姆(Zhou xinyu,Zhou Xinyu,Zhou Xinyu,Zhou Xinyu)拉入一个小房间带老师Qiu(Zhejiang)的房间。 University/Zhijiang实验室Qiu Jiezhong是MOBA Idea的建议者)和Dylan(月球黑暗面的研究人员)开始长期培训。首先,我要感谢蒂姆的耐心和教学。在寄予厚望并愿意培养它们并开发了各种在线模型和与模型相关的技术的大个子中,其中许多基本上是从头开始与LLM联系,就像我一样。
当时,该行业不是很高。每个人都在4K中进行预训练(模型可以处理的输入和输出长度约为4000个令牌和数千个汉字)。该项目在开始时在16B上被称为16K,这意味着16B(模型参数仅进行16k长度的预训练(预训练)160亿美元),当然,这一需求很快就需要在支持下支持128K预训练。这也是MOBA设计中的第一个要求。从头开始可以快速训练可以支持128K长度的型号。目前,不需要继续培训(持续培训,并根据训练有素的模型继续培训)。
这里还提出了一个有趣的问题。在2019年5月/6月,该行业通常认为训练长期端到端培训(具有长文本培训模型)比训练较短的模型要好。找到一种种植它的方法。这种看法仅在23年的下半年发生了变化,当时长长的美洲驼(由Meta开发的大型模型支持长文本处理)。我们自己也进行了严格的验证。实际上,短文本训练 +长度激活具有更好的令牌效率(每个令牌贡献的有效信息量意味着模型可以使用更少的令牌完成更高质量的任务)。天然MOBA设计中的第一个功能成为时代的眼泪。
在此期间,MOBA的结构设计也更加“激进”。与当前的“非常简化”的结果相比,最初提出的MOBA是一种引起注意的注意机制(两个不同文本数据之间的关系的过程)。 )两层注意机制串行解决方案GATE(控制输入数据如何分配各个专家网络之间的权重)本身是一种非参数结构(无参数,无需数据培训),但是为了更好地学习历史记录令牌,我们向每个变压器层之间的机器和相应参数之间的交叉注意(可以更好地记住历史信息)。目前,MOBA设计将上下文并行的想法结合在一起,该想法以后众所周知(完整的上下文序列存储在不同的节点上,并且在需要计算时集中在一起)。我们将整个上下文序列分布在数据并行节点之间,将每个数据平行节点中的上下文视为MOE的专家(专家,专家混合系统的混合物),并将需要注意的令牌发送给相应的专家的代币,以获取相应的专家引起注意,然后传达结果。返回。我们将FastMoE(一个早期MOE培训的框架)集成到Megatron-LM(现为NVIDIA的通用模型培训框架)中,以支持专家之间的通信能力。
我们称这个想法MOBA V0.5。
(编者注:MOBA受到当前主流大型MOE结构的启发。Moe是指以下事实:当大型模型工作时,只有某些专家的参数一次激活,而不是全部,而不是全部,从而节省了计算能力;核心想法是核心想法MOBA“只有每次”。
随着时间的流逝,到8月23日初,主要模型预训练已经培训了大量令牌,而再次进行的代币并不低。 MOBA显着改变了结构并添加了其他参数,它首次进入了神社的悬崖。
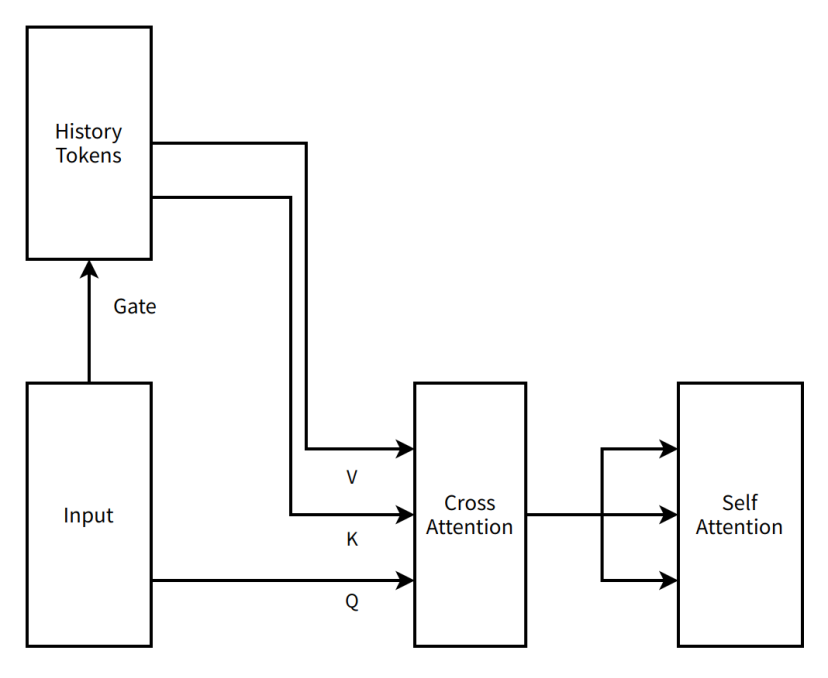
MOBA V0.5的非常简单的图
编者注:
历史令牌 - 在诸如自然语言处理之类的情况下,它代表了先前处理的文本单元的集合。
门 - 用于控制神经网络中信息流的结构
输入 - 模型收到的数据或信息
v(value) - 在注意机制中,它包含实际要处理或关注的数据内容,例如语义向量等。
k(关键标签) - 在注意机制中,标识标签用于识别信息,例如数据特征或位置,以与其他数据匹配相关联
Q(Querry Query) - 一种用于从注意机制中从键值配对中检索相关信息的向量
引起关注 - 一种关注机制,重点是来自不同来源的输入,例如将输入与历史信息相关联
自我关注 - 一种注意机制,模型专注于自己的输入并捕获输入中的依赖项
进入思想悬崖后
进入思想悬崖当然是个玩笑,现在是时候停下来寻找改进计划了,也是时候深入了解新结构了。我第一次进入悬崖并意识到真相时,我很快进来并迅速出来。作为《黑暗面的想法》之王,蒂姆提出了一个新的改进想法,并将MOBA从串行的两层注意力方案转变为平行的单层注意力方案。 MOBA不再添加其他模型参数,而是使用现有的注意机制参数来同步序列中的所有信息,因此当前的结构可用于尽可能继续训练。
我们称这个想法MOBA V1。
MOBA V1实际上是稀疏注意背景平行的产物。当当时的上下文并行不流行时,MOBA V1表现出极高的端到端加速能力。在我们验证它在3B和7B上有效后,我们以较大的模型量表水平撞到墙壁,并且在训练过程中发生了非常大的损失尖峰(在模型训练过程中发生的异常)。我们合并关注输出的方法的初始版本(关注模块处理数据后的结果)太肤浅了,这只是一个简单的积累真相(标准答案,这里是指完全关注的结果)调试非常困难,当时我们使用了各种稳定方法,无法解决。由于较大模型的培训问题,MOBA进入了思维的悬崖。
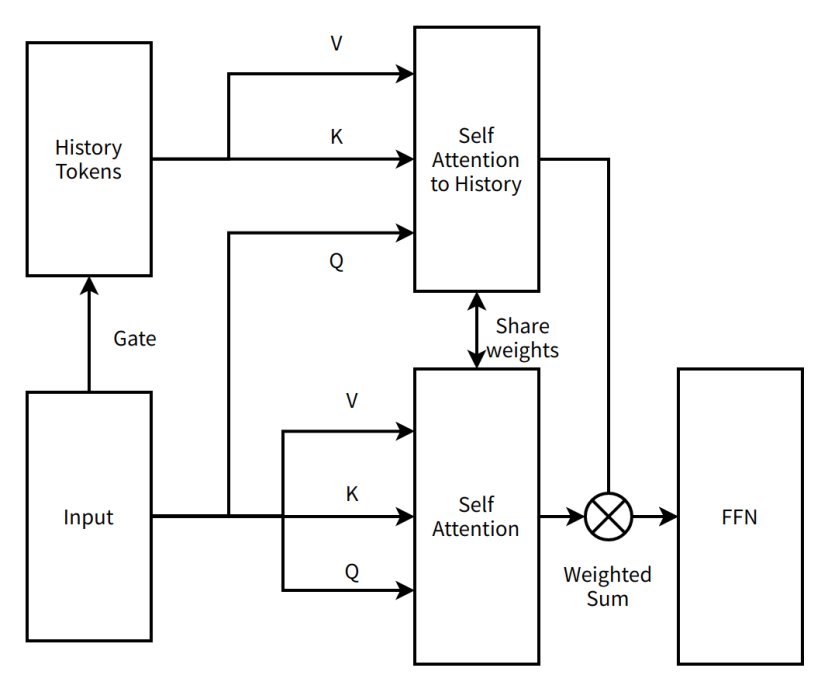
MOBA V1的非常简单的图
编者注:
自我关注对历史 - 一种注意机制,模型侧重于历史标记并捕获当前输入和历史信息之间的依赖性
共享权重 - 神经网络的不同部分使用相同的权重参数来减少参数的数量并提高模型概括功能
FFN(feed - 正向神经网络) - 基本的神经网络结构,其中数据从输入层从隐藏层流向单个方向的输出层
加权总和 - 总和根据其各自的权重
其次,进入思想悬崖
从9月23日开始,我第二次在Siguo Cliff呆了很长时间,已经是24年前。但是,在思想悬崖上并不意味着被放弃。我能够体验到在月球黑暗面(饱和救援)工作的第二个主要特征。
除了蒂姆(Tim)和老师Qiu(Qiu),他们已经强烈地输出了,Su Shen(Su Jianlin(Su Jianlin),月球黑暗的一面研究员),Yuan GE(月球黑暗面的研究人员Jingyuan Liu)和所有大的伙计们参加了激烈的讨论,并开始拆除。为了解决和纠正MOBA,要纠正的第一件事是简单的加权总和(加权总和)叠加。在我们尝试了各种乘法和添加门矩阵的方法之后,蒂姆从一堆旧论文中删除了在线softmax(如果他看到所有数据,还可以处理一个数据,他不仅可以计算出来),并说这应该有效好的。最大的好处之一是,在使用在线SoftMax之后,我们可以通过将稀疏度减少到0(选择所有块),以数学上等效的全部关注来严格控制调试,从而解决了大多数实施情况。出现的问题。但是,数据并行节点之间的上下文分裂的设计仍会导致不平衡问题。数据样本在数据并行性之间铺有瓷砖之后,将大力遵循第一个数据并行等级的标头令牌。 q发送(注意计算过程),使平衡极差,从而降低了加速度的效率。这种现象也有一个更广为人知的名称 - 注意下沉。
目前,张老师访问了我们的想法,他提出了一个新想法,将上下文平行能力与MOBA分开。上下文平行是背景平行的,MOBA是MOBA,MOBA回归了稀疏的注意力本身,而不是分布式的稀疏注意训练框架。只要存储视频,所有上下文就可以在独立的机器上处理,并且计算加速度可用于组织和传输机器之间的上下文通过上下文并行。因此,我们重新完成了MOBA V2,这基本上是我们现在看到的MOBA。
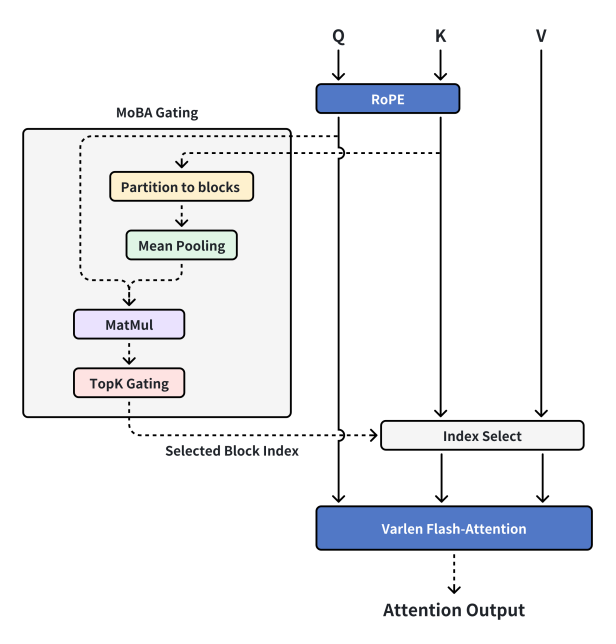
当前的MOBA设计
编者注:
MOBA Gating(MOBA Gating) - MOBA中的特定门控机制
绳索(旋转位置嵌入) - 一种将位置信息添加到序列的技术
分区到块 - 将数据分为不同的块
平均合并 - 在深度学习中进行下样本数据的操作,以计算该地区数据的平均值
MatMul(矩阵 - 乘数矩阵乘法) - 用于计算两个矩阵乘积的数学操作
Topk Gating(顶部 - k门) - 选择第一个K重要元素和其他操作的门控机制
选定的块索引 - 取代所选块的数量
索引选择 - 根据索引从数据中选择相应的元素
VARLEN闪存注意力 - 一种适合可变长度序列的注意机制,并且在计算上是有效的
注意输出 - 计算注意力机制后的输出结果
MOBA V2稳定且可训练,短文和完全关注的关注完全对齐,缩放定律看起来非常可靠,并且柔滑的支撑促进了在线模型。因此,我们添加了更多资源。在为学生提供了一系列调试和消耗N组的头发,我们可以使用MOBA激活的预处理模型来测试完整的绿色测试(大型型号处理很长时间,我们已经认为这是非常出色的,并且开始在线上进行上网。
但是最不惊讶的是事故。 SFT(基于训练前模型的监督微调,进一步培训模型的特定任务以提高模型在该任务上的性能)阶段部分伴随着一个非常稀疏的丢失面具(只有1%的蒙版甚至更少的令牌具有训练梯度)(丢失面膜是指选择模型的哪些部分参与预测结果和标准答案的技术),这导致MOBA在大多数SFT上的表现良好任务,但是文章总结了任务类型的时间越长,丢失了面具越稀疏,反映在其中的效率就越少。在准上线过程中,将MOBA按在暂停按钮上,第三次进入Shuiguo悬崖。
思想的三个娱乐
当我第三次进入Siguo Cliff时,整个项目的沉没成本很高,公司支付了许多计算资源和人力资源。如果端到端长期文章的应用程序方案存在问题,那么早期研究即将融化。幸运的是,由于MOBA本身具有出色的数学特性,在新一轮饱和救援的实验消融中(消融实验,通过删除模型的某些部分或更改某些设置以研究其对模型性能的影响),我们发现删除损失面具是非常好的,但是戴上损失面具并不令人满意,然后意识到它是带有梯度的令牌(使用的方向和步骤尺寸的值在机器学习以在方向和步长以更新模型参数的情况下)SFT阶段太稀疏了,这带来了学习效率低下的问题。因此,通过修改最后几层以全心关注,在反向传播过程中梯度令牌的密度得到了提高,并提高了特定任务的学习效率。随后的其他实验表明,转换后这种切换不会显着影响稀疏的注意力效应,并且与1M长度(100万)相同结构的全部注意指标相同。 MOBA已从Siguo Cliff返回,并成功地在线推出以服务用户。
最后,我要感谢所有伟大的大师的帮助,公司的强大支持和巨大的图形卡。我们现在正在开放的是我们在线使用的代码,这是一种稀疏的注意结构,由于实际要求,已经经过了很长时间的验证,该要求已切断了各种其他设计,它保持了简约的结构,但具有足够的效果。我希望BOBA和诞生的COT(思想链)可以为所有人带来一些帮助和价值。
常问问题
顺便说一句,我借了一个地方来回答过去两天经常问的一些问题。我基本上要求张老师和Su Shen回答过去两天的客户服务问题。我真的很抱歉。在这里,我提出了一些常见的问题,并一起回答了。
1。MOBA无效解码(模型推理阶段中的文本生成过程)?
MOBA对解码有效,对MHA非常有效(多头注意力),对GQA(分组查询注意)的有效性较低,并且对MQA(多质量注意)更敏感。该原理实际上很简单。在MHA的情况下,每个Q都有自己的相应KV缓存。在理想的情况下,可以通过摊销计算和存储MOBA门(首次处理输入时的计算阶段)。每个块的代表令牌(数据块)将来不会更改,因此仅在索引选择后,只能从KV缓存(通过索引选择数据的操作)基本上仅通过KV缓存才能实现。在这种情况下,MOBA的稀缺性决定了IO降低的程度。
但是对于GQA和MQA来说,由于一组Q头实际上共享了相同的KV缓存,因此,当每个Q头可以自由选择感兴趣的块时,很可能会填补每个Q的情况所带来的稀疏度头可以自由选择感兴趣的块,很可能会充满IO优化带来的稀疏度。例如,我们考虑一个方案:16 Q HEAD MQA,MOBA只是将整个序列分为16份,这意味着在最坏的情况下,每个Q头对每个上下文块都感兴趣,序列号为1到16。保存IO的优势将被弄平。您可以从KV块中选择的Q头越多,效果越糟。
由于存在“自由选择Q头”的现象,因此改进的自然思想是合并。如果每个人都选择相同的块,是否会为净利润进行优化吗?是的,但是在我们的实际测试下,尤其是对于已经支付了很多费用的预训练的模型,每个Q头部都有其独特的“口味”。强行组合不如从头开始重新培训。
2.默认情况下,Moba是必需的自我关注机制,因此需要Self的邻居吗?
这是不必要的。这是一些疑问的地方。我们最终选择相信SGD(随机梯度下降)。当前的MOBA门实现非常直接。有兴趣的学生可以简单地转换大门,以便它必须选择一个块(数据块),但是我们测试了利润带来的好处(不多)。
3。MOBA是否有Triton(撰写由OpenAI开发的高性能GPU代码的框架)?
我们已经实施了一个版本,其端到端性能提高10%++,但是Triton实施以跟上主线的成本相对较高,因此我们在多次迭代后推迟了进一步的优化。
*本文开头提到的几个成就的项目地址(GitHub页面包含技术论文链接,DeepSeek尚未启动NSA的GitHub页面):
moba github页面:
NSA技术论文:
minimax-01 github页面:
INFLLM GITHUB页面:
Seerattention github页面: